이 기사 education.io ~에서 Grokking 현대 시스템 설계 인터뷰 이것은 과정의 도메인 이름 시스템 장의 내용을 요약한 기사입니다.
DNA의 기원
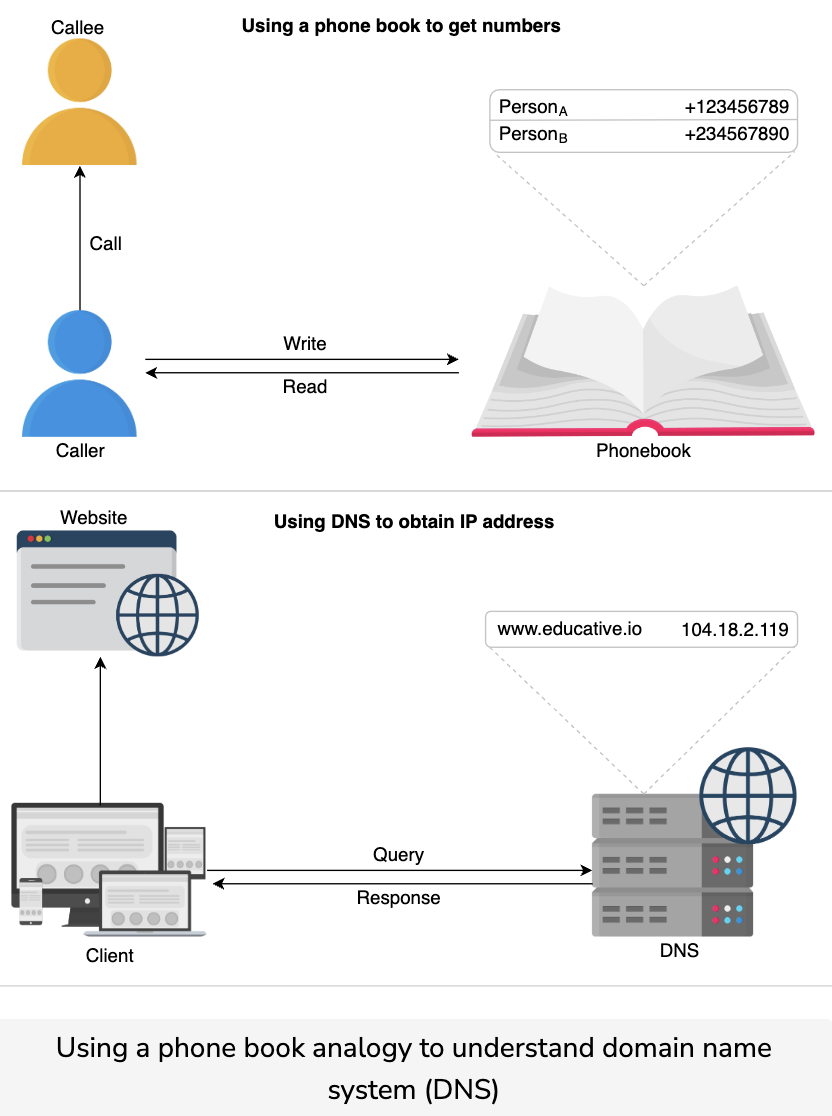
휴대폰에는 각 사용자와 관련된 고유한 전화 번호가 있습니다. 친구에게 전화를 걸려면 먼저 친구의 전화번호를 기억해야 합니다. 기억해야 할 연락처가 늘어남에 따라 전화번호부를 관리하고 필요할 때 원하는 사람에게 전화를 걸어 연락처를 관리할 수 있습니다.
마찬가지로 컴퓨터는 고유한 IP 주소로 서로 구별할 수 있습니다. IP 주소를 사용하여 특정 컴퓨터에서 호스팅하는 웹 사이트를 방문합니다. 그러나 사람들이 도메인 이름을 방문하기 위해 모든 IP 주소를 기억하기 어렵기 때문에 모든 도메인 이름을 IP 주소로 매핑을 유지하기 위해 전화번호부와 같은 리포지토리를 가질 수 있습니다. DNS가 인터넷에서 전화번호부 역할을 하는 방법을 살펴보겠습니다.
DNA 란 무엇입니까?
DNS(도메인 이름 시스템)는 인간에게 친숙한 도메인 이름을 기계가 읽을 수 있는 IP 주소에 매핑하는 인터넷 이름 지정 서비스입니다.
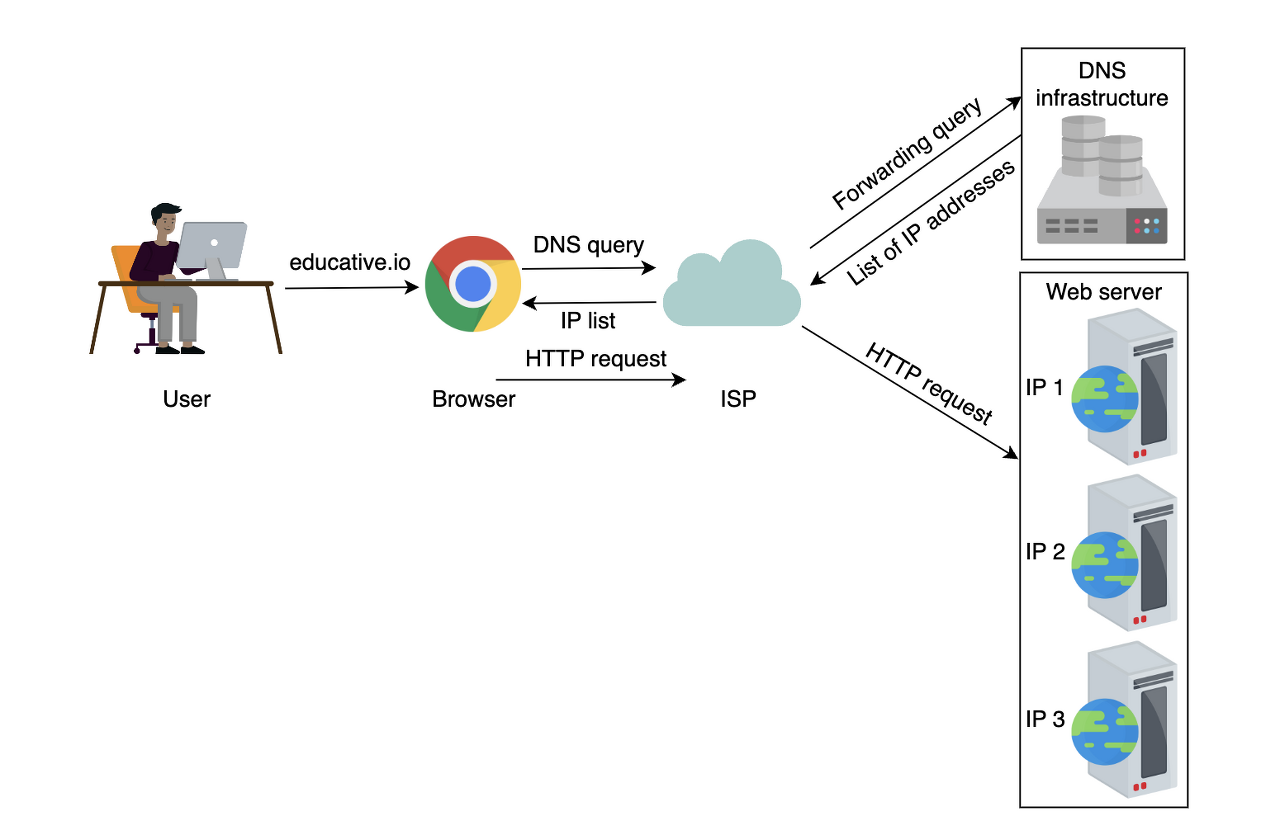
사용자가 브라우저에 도메인 이름을 입력하면 브라우저는 도메인 이름을 IP 주소로 변환하기 위해 DNS 인프라를 쿼리해야 합니다. IP 주소가 확보되면 사용자의 요청이 대상 웹 서버로 전달됩니다.
이러한 작업은 매우 빠르게 수행되며 사용자는 최소한의 지연을 경험합니다.
중요한 세부 정보
- 이름 서버
- DNS는 단일 서버가 아니라 여러 서버로 구성된 완전한 인프라입니다.
- 사용자 쿼리에 응답하는 DNS 서버를 이름 서버라고 합니다.
- 리소스 레코드
- DNS DB는 도메인 이름과 IP 주소의 매핑을 리소스 레코드(RR) 형식으로 저장합니다.
- RR은 사용자가 네임서버에 요청하는 정보의 최소 단위입니다.
- RR에는 다음과 같은 몇 가지 유형이 있습니다.
유형 이름 값 설명 예(유형, 이름, 값)
| 유형 | 성 | 값 | 설명 | 예(유형, 이름, 값) |
| ㅏ | 호스트 이름 | IP 주소 | 호스트 이름 → IP 주소 할당 | (ㅏ, relay.main.educative.io104.18.2.119) |
| NS | 도메인 이름 | 호스트 이름 | 도메인 이름 → 신뢰할 수 있는 DNS의 호스트 이름 | (NS, education.io, dns.educative.io) |
| CNAME | 호스트 이름 | 독특한 명칭 | 별칭 → 정식 호스트 이름 매핑 | (CNAME, education.io, server1.primary.educative.io) |
| 멕시코 | 호스트 이름 | 독특한 명칭 | 메일 서버 별칭 → 정식 호스트 이름 | (멕시코, mail.educative.io, mailserver1.backup.educative.io) |
- 캐싱
- DNS는 다양한 수준에서 캐싱을 사용하여 사용자 요청 대기 시간을 줄입니다.
- DNS 인프라는 인터넷을 통한 요청을 수용해야 하므로 캐싱은 부하를 줄이는 데 중요한 역할을 합니다.
- 계층
- DNS 이름 서버는 계층적입니다.
- 계층 구조는 계속 증가하는 크기와 쿼리 부하로 DNS의 높은 확장성을 허용합니다.
DNS 계층
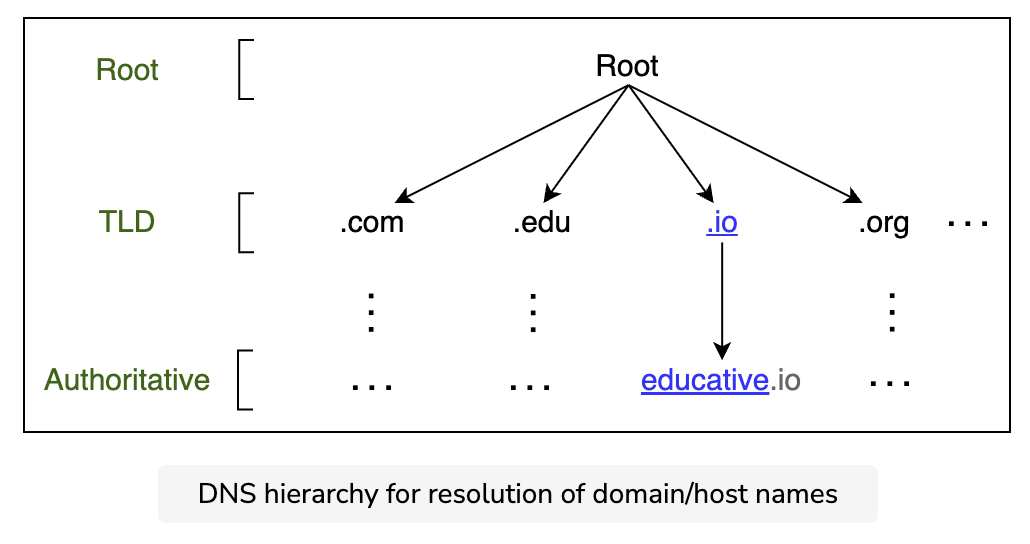
앞에서 언급했듯이 DNS는 단일 서버가 아니라 여러 서버로 구성된 완전한 인프라입니다.
DNS 계층 구조는 주로 네 가지 유형의 서버로 구성됩니다.
- DNS 리졸버
- 쿼리 시퀀스를 시작하고 쿼리를 다른 DNS 이름 서버로 전달
- 일반적으로 사용자 자신의 네트워크 내에 있음
- 캐시를 사용하여 DNS 쿼리를 빠르게 제공할 수도 있습니다.
- 로컬 또는 기본 서버라고도 함
- 루트 수준 이름 서버
- 로컬 서버에서 요청 받기
- .com, .edu 및 .us와 같은 최상위 도메인 이름에 따라 네임서버를 관리합니다.
- education.io io 요청에서 루트 수준 이름 서버는 .io 도메인에 IP 주소가 있는 최상위 도메인(TLD) 서버 목록을 반환합니다.
- 최상위 도메인(TLD) 이름 서버
- 신뢰할 수 있는 이름 서버의 IP 주소가 있는 서버
- 쿼리는 조직의 신뢰할 수 있는 서버에 속한 IP 주소를 반환합니다.
- 신뢰할 수 있는 이름 서버
- 쿼리된 웹 서버 또는 지도 서버의 IP 주소를 제공하는 조직의 DNS 이름 서버입니다.
묻다
: DNS 이름은 어떻게 처리됩니까? 예를 들어, education.io 왼쪽에서 오른쪽으로 또는 오른쪽에서 왼쪽으로 처리됩니까?
→ UNIX 파일과 달리 DNS 이름은 오른쪽에서 왼쪽으로 처리됩니다. 리졸버는 먼저 .io를 확인한 다음 해당 순서로 유익합니다.
반복 대 재귀 쿼리 해결
두 가지 DNS 쿼리 방법
- 반복적 인
- 로컬 서버는 루트 → TLD → 권한 있는 서버 순서로 요청을 보냅니다.
- 재귀
- 사용자가 로컬 서버에 요청을 보내면 로컬 서버는 루트 DNS 네임서버를 요청합니다.
- 루트 이름 서버는 요청을 다른 이름 서버로 전달합니다.
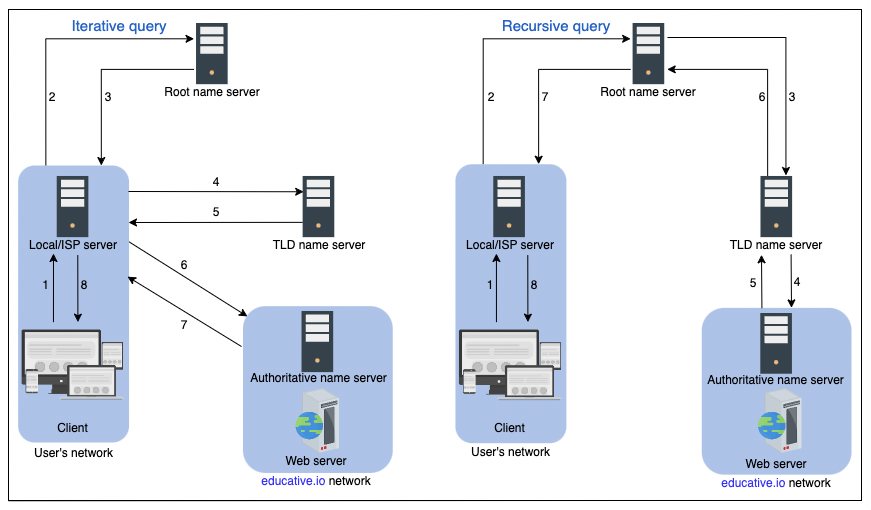
반복 쿼리는 일반적으로 DNS 인프라의 부하를 줄일 수 있으므로 선호됩니다.
오늘날 퍼블릭 DNS 리졸버는 Google 및 Cloudflare와 같은 타사 제공업체에서 제공하며 이러한 DNS 서버는 종종 로컬 ISP DNS 시설보다 빠른 응답을 제공합니다.
https://developers.google.com/speed/public-dns?hl=de
캐싱
캐싱은 자주 요청되는 리소스 레코드를 임시로 저장하는 것을 말합니다. 레코드는 이름-값 바인딩을 나타내는 DNS 데이터베이스의 데이터 단위입니다. 캐싱은 사용자 응답 시간과 네트워크 트래픽을 줄입니다. 여러 계층에서 사용하는 경우 캐싱은 DNS 인프라에서 많은 쿼리의 부하를 줄일 수 있습니다. 캐싱은 브라우저, 운영 체제, 사용자 네트워크의 로컬 이름 서버 또는 ISP의 DNS 확인자에서 구현할 수 있습니다.
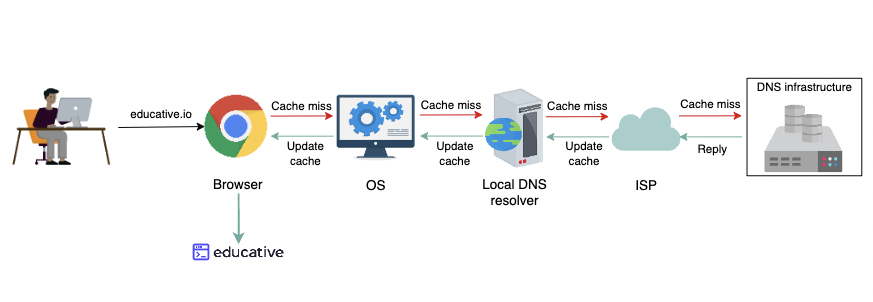
분산 시스템으로서의 DNS
- 분산 시스템의 장점
- SPOF가 되지 않도록
- 사용자가 인근 서버에서 응답을 받을 수 있도록 하면서 쿼리 대기 시간을 줄입니다.
- 유지 관리 및 업그레이드를 위한 높은 수준의 유연성 제공
- A부터 M까지 이름이 지정된 13개의 루트 이름 서버가 있으며 서버 인스턴스는 전 세계에 분산되어 있습니다. 이 서버는 12개의 서로 다른 조직에서 관리합니다.
- https://www.iana.org/domains/root/servers
높은 확장성
- 13개의 루트 수준 서버의 복제된 인스턴스 약 1,000개가 사용자 요청을 처리하기 위해 전 세계에 전략적으로 분산되어 있습니다.
- 쿼리 처리 워크로드는 TLD, 루트 서버 및 조직 자체에서 관리하는 권한 있는 서버 간에 분산 및 처리됩니다.
- DNS 계층 구조에서 보았듯이 서로 다른 서비스가 계층 구조의 서로 다른 부분을 처리하므로 시스템을 확장 및 관리할 수 있습니다.
믿을 수 있는
DNS를 신뢰할 수 있는 시스템으로 만드는 세 가지 요소가 있습니다.
- 은닉처
- 여러 수준에서 작동하는 캐싱은 자주 방문하는 서비스의 풍부한 캐시를 유지합니다.
- DNS 서버가 잠시 다운되더라도 캐시된 레코드를 제공할 수 있어 DNS 시스템을 안정적으로 만듭니다.
- 서버 복제
- 지연 시간이 짧은 사용자 요청을 처리하기 위해 전 세계의 DNS 복제 논리 서버.
- 중복 서버는 전반적인 시스템 안정성을 향상시킵니다.
- 규약
- 많은 클라이언트가 DNS를 신뢰할 수 없는 UDP(사용자 데이터그램 프로토콜)로 사용하지만 UDP에도 장점이 있습니다.
- UDP는 빠르기 때문에 DNS의 성능을 향상시킵니다.
- 또한 인터넷 서비스의 신뢰성이 초창기보다 더 발전했기 때문에 TCP보다 UDP가 일반적으로 선호됩니다.
- DNS 확인자는 이전 요청이 응답되지 않은 경우 UDP 요청을 다시 보낼 수 있습니다.
- 이 요청-응답은 왕복으로 수행될 수 있으므로 데이터를 교환하기 전에 3방향 핸드셰이크가 필요한 TCP보다 대기 시간이 짧습니다.
묻다
: 네트워크가 혼잡할 때 DNS는 UDP를 계속 사용해야 합니까?
→ 일반적으로 UDP를 사용하지만 메시지 크기가 원래 패킷 크기인 512B를 초과하는 경우 TCP를 사용할 수 있습니다. 큰 패킷은 혼잡한 네트워크에 더 취약하기 때문입니다. DNS는 영역 전송에 항상 TCP를 사용합니다. 또한 일부 클라이언트는 TCP를 사용하여 개인 정보 보호를 위해 전송 계층 보안을 사용합니다.
일관된
DNS는 다양한 프로토콜을 사용하여 계층적 복제 서버 간에 정보를 업데이트하고 전송합니다. DNS는 쓰기보다 읽기가 더 많기 때문에 높은 성능을 얻기 위해 강한 일관성을 포기합니다. 그러나 DNS는 최종 일관성을 제공하며 복제된 서버에서 레코드 업데이트가 느립니다. 일반적으로 인터넷의 DNS 서버에서 레코드가 업데이트되는 데 몇 초에서 3일이 걸릴 수 있습니다. 서로 다른 DNS 클러스터 간에 정보가 전파되는 데 걸리는 시간은 DNS 인프라, 업데이트 크기 및 업데이트되는 DNS 구조 부분에 따라 다릅니다.
캐싱은 또한 일관성을 감소시킬 수 있습니다. 신뢰할 수 있는 서버는 조직 내에 상주하므로 조직에 서버 오류가 발생하면 특정 리소스 레코드가 업데이트될 수 있습니다. 이 경우 캐시된 레코드는 표준/로컬 및 ISP 서버에서 만료될 수 있습니다. 이 문제를 해결하기 위해 캐시된 각 레코드에는 TTL(Time-to-Live)이라는 만료 시간이 있습니다.
묻다
: 고가용성을 위해 TTL이 작아야 합니까? 나는 자라야 하는 걸까?
→ 고가용성을 위해서는 TTL 값이 작아야 합니다. 이는 조직이 서버 또는 클러스터 장애 시 리소스 레코드를 즉시 업데이트할 수 있기 때문입니다. 사용자는 TTL이 만료되지 않은 기간 동안만 사용할 수 있습니다. 그러나 TTL이 높으면 조직에서 리소스 레코드를 업데이트하지만 사용자는 오래 전에 죽은 오래된 서버를 ping하고 있을 수 있습니다. 고가용성을 목표로 하는 조직은 TTL 값을 120초로 낮게 유지하여 정전 시에도 최대 가동 중지 시간을 몇 분으로 제한합니다.
사용해 보세요
- nslookup
- 신뢰할 수 없는 응답은 Google의 신뢰할 수 있는 서버가 아닌 서버에서 제공하는 응답입니다.
- 이 답변은 요청에 응답하는 두 번째, 세 번째, 네 번째… 문장입니다. 이것은 네임서버의 응답입니다.
- 예를 들어 사무실 DNS 리졸버, ISP 네임서버, ISP의 ISP 네임서버 등.
- 간단히 말해 Google의 신뢰할 수 있는 이름 서버 응답의 캐시된 버전입니다.
- 여러 도메인 이름을 시도하면 캐시된 응답이 발생할 가능성이 큽니다.
- 동일한 명령을 여러 번 실행하면 동일한 IP 주소를 다른 순서로 나열하는 응답이 생성될 수 있습니다. DNS가 간접적으로 부하 분산을 수행하기 때문입니다.
$ nslookup www.google.com
Server: 168.126.63.1
Address: 168.126.63.1#53
Non-authoritative answer:
Name: www.google.com
Address: 142.250.76.132
- 파기
- 쿼리 시간은 DNS 서버에서 응답을 받는 데 걸리는 시간입니다.
- ANSWER SECTION의 값 161은 캐시 항목이 유지되는 시간(초)을 나타냅니다.
$ dig www.google.com
; <<>> DiG 9.10.6 <<>> www.google.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 30848
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;www.google.com. IN A
;; ANSWER SECTION:
www.google.com. 161 IN A 142.250.206.228
;; Query time: 23 msec
;; SERVER: 168.126.63.1#53(168.126.63.1)
;; WHEN: Sun Mar 19 18:56:50 KST 2023
;; MSG SIZE rcvd: 59
묻다
: 웹사이트에 접속하기 위해 IP 주소를 알려주기 위해 DNS가 필요한 경우, DNS 리졸버 IP 주소를 찾는 방법은 무엇입니까?
→ 사용자 운영 체제에 DNS 리졸버 IP가 포함된 구성 파일(/etc/resolv.conf 등)이 있습니다.